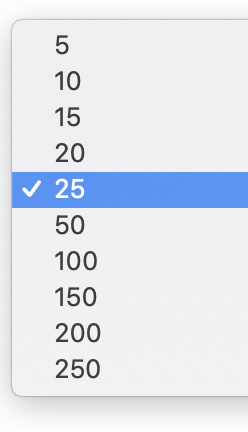
Currently the table grid visualisation defaults to 10 and has an upper limit bound of 25.
When working with larger datasets this is particularly painful. Paging through even a few hundred rows looking for an anomaly in data is not a fun time.
We suggest making this configurable via two variables similar to what has been implemented by the mighty Japanese Redash Meetup.
The query pull request is here: Add page size settings by kyoshidajp · Pull Request #2993 · getredash/redash · GitHub
I would expect that to be just the same but focusing on the table visualisation.
A similar request has had many many views, so I suspect this frustration is common.