One of the interesting challenges when exploring the Redash visualisations, is not having a handy source of data that fits well with them (for learning).
The nifty looking Choropleth maps are a case in point. They look interesting, but there’s no example data provided for playing with.
So, created some and uploaded it here for people to use:
https://dbhub.io/justinclift/DB4S%20daily%20users%20by%20country.sqlite
That’s the (real) daily users count for DB Browser for SQLite, from when we first started measuring through to a few days ago.
An example query to use with it (via the URL and Query Mapper data sources) is:
SELECT country, users
FROM query_6
WHERE date = '2019-04-22'
query_6 being the ID number of the URL data source created for it. When using this data set, your query number will have a different ID number on the end.
This is the Choropleth (map) visualisation from that query:
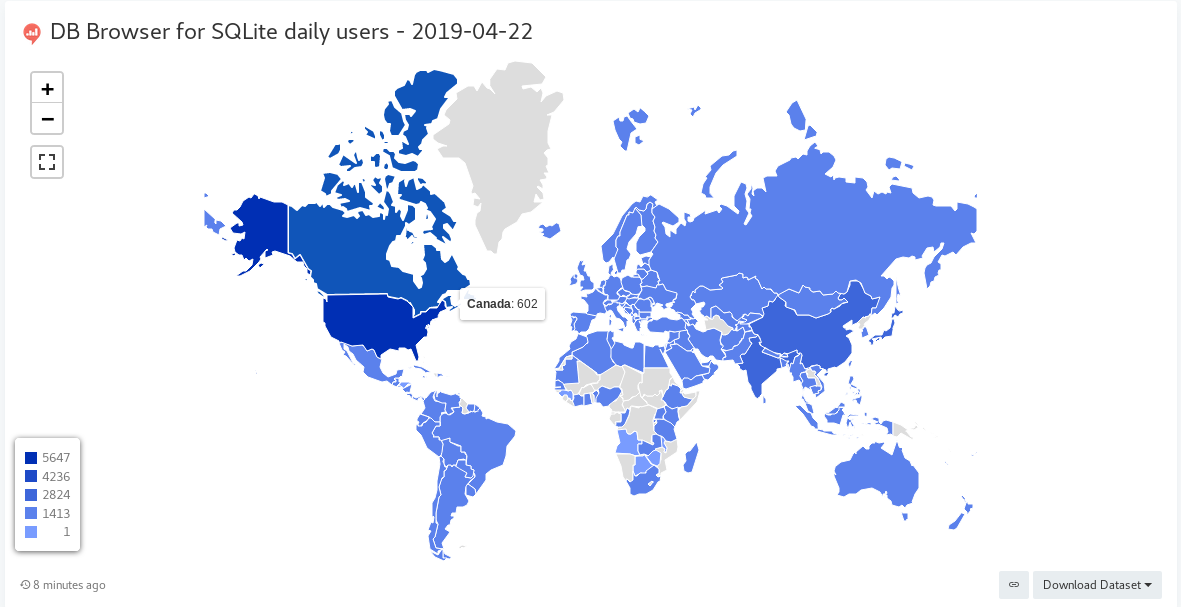
The settings used for the visualisation are:
1 Like
First, thank you! This is really great. 
But this made me wonder: how about we create a proper Query Runner for DBHub.io in Redash? There are two ways to go about it:
- Redash will download the SQLite database from DBHub.io and then run the query on it.
-
DBHub.io will expose a query execution API.
I think that #2 is better, but it means you need to execute queries now. Considering this is what happens anyway when someone uses the Redash API you created, maybe it’s not a big deal?
Wdyt?
Cool. 
A proper Query Runner interface would be good.
It’s on my eventual ToDo list, but isn’t a short term item as I need to get up to speed with Python development again (my priority atm is familiarising with LLVM code generation for a different item).
If you guys are ok with putting one together instead, that’d be awesome! And much quicker to get in place. Approach wise, I’d recommend 1. rather than 2. for now.
A query execution API is a good idea, and needs to happen at some point.
But the security implications are non-trivial to work through, and the likely additional server load while we’re pre-revenue is pretty risky. Better to not chance it at the moment, and just use the “grab the database from DBHub.io and run queries on it” approach.
Most of the databases aren’t huge (obviously depending on the data set), and with the automatic gz compression of transfers by the web server anyway, it should be reasonably efficient.
In theory. 
