postgres_1 | ERROR: column dashboards.options does not exist at character 614
postgres_1 | STATEMENT: SELECT count(*) AS count_1
postgres_1 | FROM (SELECT dashboards.updated_at AS dashboards_updated_at, dashboards.created_at AS dashboards_created_at, dashboards.id AS dashboards_id, dashboards.version AS dashboards_version, dashboards.org_id AS dashboards_org_id, dashboards.slug AS dashboards_slug, dashboards.name AS dashboards_name, dashboards.user_id AS dashboards_user_id, dashboards.layout AS dashboards_layout, dashboards.dashboard_filters_enabled AS dashboards_dashboard_filters_enabled, dashboards.is_archived AS dashboards_is_archived, dashboards.is_draft AS dashboards_is_draft, dashboards.tags AS dashboards_tags, dashboards.options AS dashboards_options
nginx_1 | 10.0.1.97 - - [07/Dec/2021:12:38:18 +0000] "GET /static/app.101c1284c4a7520ca61d.css.map HTTP/1.1" 200 173089 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" "37.228.230.71"
postgres_1 | FROM dashboards
postgres_1 | WHERE 1 = dashboards.org_id AND dashboards.is_archived = false) AS anon_1
server_1 | [2021-12-07 12:38:18,498][PID:10][ERROR][redash.app] Exception on /api/organization/status [GET]
server_1 | Traceback (most recent call last):
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 1249, in _execute_context
server_1 | cursor, statement, parameters, context
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/default.py", line 580, in do_execute
server_1 | cursor.execute(statement, parameters)
server_1 | psycopg2.errors.UndefinedColumn: column dashboards.options does not exist
server_1 | LINE 2: ...rds_is_draft, dashboards.tags AS dashboards_tags, dashboards...
server_1 | ^
server_1 |
server_1 |
server_1 | The above exception was the direct cause of the following exception:
server_1 |
server_1 | Traceback (most recent call last):
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/app.py", line 2446, in wsgi_app
server_1 | response = self.full_dispatch_request()
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/app.py", line 1951, in full_dispatch_request
server_1 | rv = self.handle_user_exception(e)
server_1 | File "/usr/local/lib/python3.7/site-packages/flask_restful/__init__.py", line 269, in error_router
server_1 | return original_handler(e)
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/app.py", line 1820, in handle_user_exception
server_1 | reraise(exc_type, exc_value, tb)
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
server_1 | raise value
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/app.py", line 1949, in full_dispatch_request
server_1 | rv = self.dispatch_request()
server_1 | File "/usr/local/lib/python3.7/site-packages/flask/app.py", line 1935, in dispatch_request
server_1 | return self.view_functions[rule.endpoint](**req.view_args)
server_1 | File "/usr/local/lib/python3.7/site-packages/flask_login/utils.py", line 261, in decorated_view
server_1 | return func(*args, **kwargs)
server_1 | File "/app/redash/handlers/organization.py", line 22, in organization_status
server_1 | models.Dashboard.org == current_org, models.Dashboard.is_archived == False
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3605, in count
server_1 | return self.from_self(col).scalar()
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3330, in scalar
server_1 | ret = self.one()
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3300, in one
server_1 | ret = self.one_or_none()
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3269, in one_or_none
server_1 | ret = list(self)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3342, in __iter__
server_1 | return self._execute_and_instances(context)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/orm/query.py", line 3367, in _execute_and_instances
server_1 | result = conn.execute(querycontext.statement, self._params)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 988, in execute
server_1 | return meth(self, multiparams, params)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/sql/elements.py", line 287, in _execute_on_connection
server_1 | return connection._execute_clauseelement(self, multiparams, params)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 1107, in _execute_clauseelement
server_1 | distilled_params,
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 1253, in _execute_context
server_1 | e, statement, parameters, cursor, context
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 1473, in _handle_dbapi_exception
server_1 | util.raise_from_cause(sqlalchemy_exception, exc_info)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/util/compat.py", line 398, in raise_from_cause
server_1 | reraise(type(exception), exception, tb=exc_tb, cause=cause)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/util/compat.py", line 152, in reraise
server_1 | raise value.with_traceback(tb)
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/base.py", line 1249, in _execute_context
server_1 | cursor, statement, parameters, context
server_1 | File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/default.py", line 580, in do_execute
server_1 | cursor.execute(statement, parameters)
server_1 | sqlalchemy.exc.ProgrammingError: (psycopg2.errors.UndefinedColumn) column dashboards.options does not exist
server_1 | LINE 2: ...rds_is_draft, dashboards.tags AS dashboards_tags, dashboards...
server_1 | ^
server_1 |
server_1 | [SQL: SELECT count(*) AS count_1
server_1 | FROM (SELECT dashboards.updated_at AS dashboards_updated_at, dashboards.created_at AS dashboards_created_at, dashboards.id AS dashboards_id, dashboards.version AS dashboards_version, dashboards.org_id AS dashboards_org_id, dashboards.slug AS dashboards_slug, dashboards.name AS dashboards_name, dashboards.user_id AS dashboards_user_id, dashboards.layout AS dashboards_layout, dashboards.dashboard_filters_enabled AS dashboards_dashboard_filters_enabled, dashboards.is_archived AS dashboards_is_archived, dashboards.is_draft AS dashboards_is_draft, dashboards.tags AS dashboards_tags, dashboards.options AS dashboards_options
server_1 | FROM dashboards
server_1 | WHERE %(param_1)s = dashboards.org_id AND dashboards.is_archived = false) AS anon_1]
server_1 | [parameters: {'param_1': 1}]
server_1 | (Background on this error at: http://sqlalche.me/e/f405)
Found the issue I think
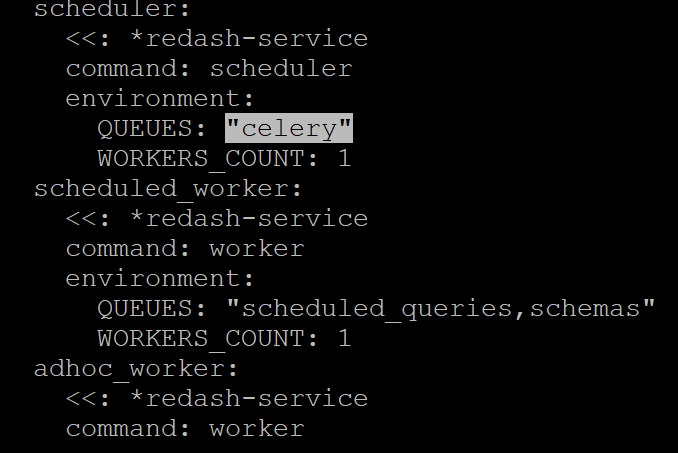


 You commented out the QUEUES and WORKER COUNT for the scheduled worker. This means your scheduled queries may not execute as expected.
You commented out the QUEUES and WORKER COUNT for the scheduled worker. This means your scheduled queries may not execute as expected.