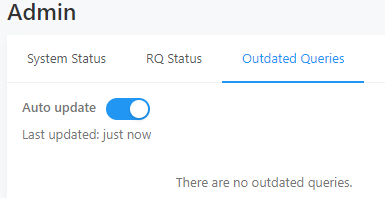
We recently successfully spin up the self-hosted redash through ECS fargate, but the scheduler seems not stable all the time. We have a couple of scheduled queries and none of them get executed ever since yesterday, and some of them are marked as “outdated query” in the system status dashboard. I couldn’t find any documentation explainning what is outdated query, besides, I walked through all the logs and nothing really helpful, not even a single error/exception found in logs. Does anyone have similiar issue?
I actually first flushed the redis and restart the worker and scheduler, then it started to work.
But I think restarting the scheduler did the trick as you said.
I’m wondering how did you come up with this idea? Why thoses scheduled queries never return results and remain outdated? Is that something related to time limit?
Also faced this issue when running the docker image - redash/redash:9.0.0-beta.b42121 (this image was built in June, 2020). Also restared scheduler but it works for a day and then same problem again.
Btw, I just noticed docker image redash/redash:preview was pushed 10days ago - which will have the latest.
Now, I want to try running the preview docker image, but, @xavier-d already said he is running preview image since more than 10days ago.
So I am kind of confused about the preview tag…
Maybe, is the preview image being overwritten by pushing new image every few days… ?
(also this image I checked has rq==1.5.0 maybe it won’t have the stuck query issues…)
I want to check the redash version that is more closer to the upcoming release of v9.
So, I need to be checking the redash/redash:preview right? not the old image redash/redash:9.0.0-beta.b42121 tag…
Sorry about my confusions and doubts… new to redash, please execuse
Indeed the image preview is overwritten with the lastest build; The one you are seeing right now (10 days ago) has for digest 0fca9eeb. I’m using it since it has been pushed (I’ve used the previous ones also).
I don’t have any issue with it on my Kubernetes infra for the refresh of the schema (that was my main concern)




 ?
?